Using Machine Learning Methods to Identify High Emission Transit Options
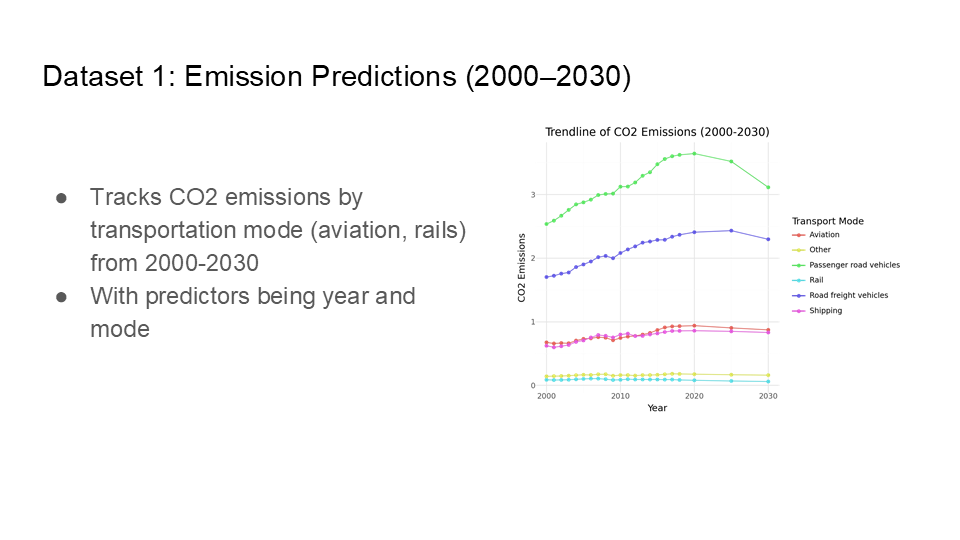
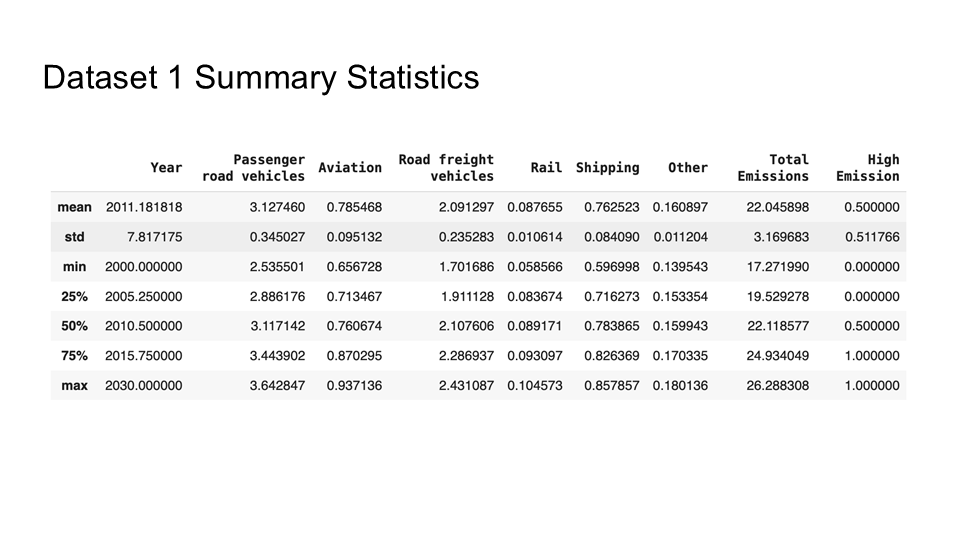
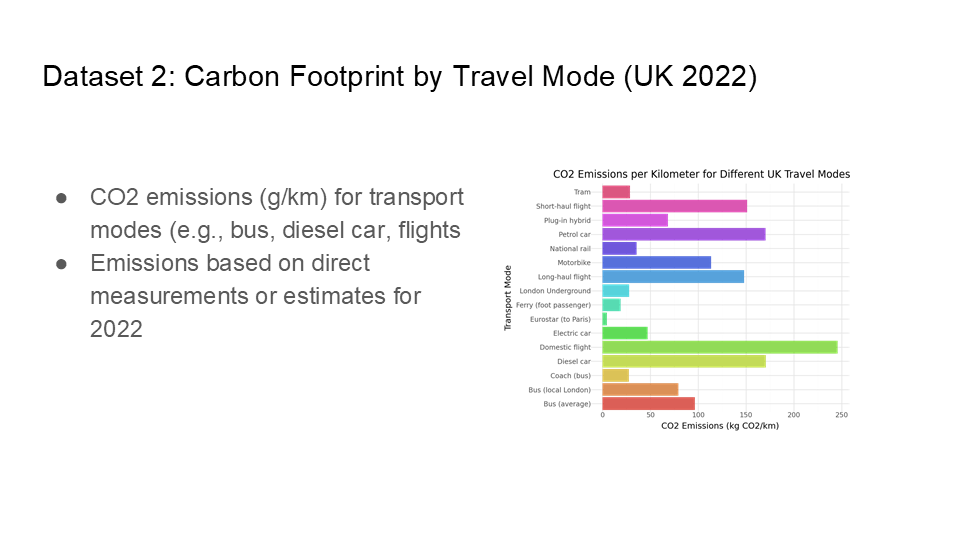
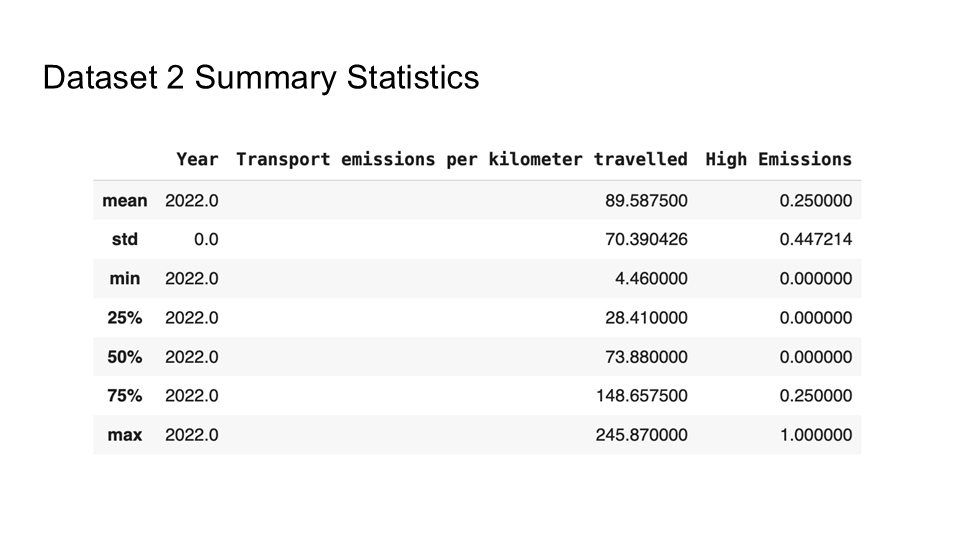
For our Machine Learning class, my team and I tackled a project aimed at identifying high-emission transportation modes and providing data-driven policy recommendations for SMART (Society for Metropolitan Analysis and Research of Transportation). Drawing on two datasets—one that forecasted CO₂ emissions from 2000 to 2030 by various transport modes, and another offering current carbon footprints by mode in the UK—we built predictive models to gauge the impact of shifting away from high-emission options toward greener alternatives. By simulating different “what-if” scenarios, we gained insight into how policy changes could substantially lower overall emissions.
In the process, we tested multiple models—including Logistic Regression, KNN, and Decision Trees—to see which best captured the relationship between year, transport mode, and potential policy interventions. Ultimately, we found that targeting road freight, aviation, and private car usage while investing in rail, electric vehicles, and active transport (like cycling) could deliver significant CO₂ reductions. If you’d like to see our Python file that demonstrates the process with code, you can find it here in my GitHub. Below are the slides we presented, detailing our methodology, the modeling outcomes, and our core recommendations for SMART’s future sustainability initiatives.